7.2 Spark运行时架构
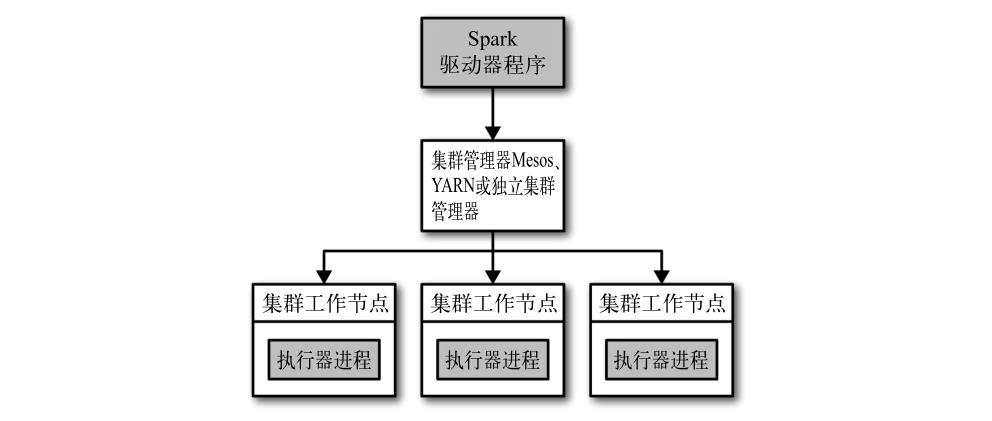
在分布式环境下,Spark 集群采用的是主 / 从结构。在一个 Spark 集群中,有一个节点负责中央协调,调度各个分布式工作节点。
这个中央协调节点被称为驱动器(Driver)节点,与之对应的工作节点被称为执行器(executor)节点。
驱动器节点可以和大量的执行器节点进行通信,它们也都作为独立的 Java 进程运行。
驱动器节点和所有的执行器节点一起被称为一个 Spark 应用(application)。
Spark 应用通过一个叫作集群管理器(Cluster Manager)的外部服务在集群中的机器上启动。
Spark 自带的集群管理器被称为独立集群管理器。
Spark 也能运行在 Hadoop YARN 和 Apache Mesos 这两大开源集群管理器上。
驱动器节点
Spark 驱动器是执行你的程序中的 main() 方法的进程。
它执行用户编写的用来创建 SparkContext、创建 RDD,以及进行 RDD 的转化操作和行动操作的代码。
- 把用户程序转为任务
Spark 驱动器程序负责把用户程序转为多个物理执行的单元,这些单元也被称为任务(task)。 所有的 Spark 程序都遵循同样的结构:程序从输入数据创建一系列 RDD,再使用转化操作派生出新的 RDD,最后使用行动操作收集或存储结果 RDD 中的数据。 - 为执行器节点调度任务
有了物理执行计划之后,Spark 驱动器程序必须在各执行器进程间协调任务的调度。
执行器节点
Spark 执行器节点是一种工作进程,负责在 Spark 作业中运行任务,任务间相互独立。
Spark 应用启动时,执行器节点就被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。
执行器进程有两大作用:
- 它们负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程;
- 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。
RDD 是直接缓存在执行器进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
集群管理器
Spark 依赖于集群管理器来启动执行器节点,而在某些特殊情况下,也依赖集群管理器来启动驱动器节点。
启动一个程序
不论你使用的是哪一种集群管理器,你都可以使用 Spark 提供的统一脚本 spark-submit 将你的应用提交到那种集群管理器上。
通过不同的配置选项, spark-submit 可以连接到相应的集群管理器上,并控制应用所使用的资源数量。
小结
- 用户通过 spark-submit 脚本提交应用。
- spark-submit 脚本启动驱动器程序,调用用户定义的 main() 方法。
- 驱动器程序与集群管理器通信,申请资源以启动执行器节点。
- 集群管理器为驱动器程序启动执行器节点。
- 驱动器进程执行用户应用中的操作。
根据程序中所定义的对 RDD 的转化操作和行动操作,驱动器节点把工作以任务的形式发送到执行器进程。 - 任务在执行器程序中进行计算并保存结果。
- 如果驱动器程序的 main() 方法退出,或者调用了 SparkContext.stop() ,驱动器程序会终止执行器进程,并且通过集群管理器释放资源。