HTML 解析器 JSoup 的基本使用
JSoup 介绍
JSoup 是一个用于处理 HTML 的 Java 库,它提供了一个非常方便类似于使用 DOM,CSS 和 jquery 的方法的 API 来提取和操作数据。
- 官网:https://jsoup.org/
- GitHub:https://github.com/jhy/jsoup/
JSoup 功能
jsoup 实现 WHATWG HTML5 规范,并将 HTML 解析为与现代浏览器相同的 DOM。
- 从 URL,文件或字符串中提取并解析 HTML。
- 查找和提取数据,使用 DOM 遍历或 CSS 选择器。
- 操纵 HTML 元素,属性和文本。
- 根据安全的白名单清理用户提交的内容,以防止 XSS 攻击。
- 输出整洁的 HTML。
JSoup 引入
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>JSoup 主要类
大多数情况下,下面给出 3 个类是我们需要重点了解的。
Jsoup 类
Jsoup 类是任何 Jsoup 程序的入口点,并将提供从各种来源加载和解析 HTML 文档的方法。
Jsoup 类的一些重要方法如下:
| 方法 | 描述 |
|---|---|
static Connection connect(String url) |
创建并返回 URL 的连接。 |
static Document parse(File in, String charsetName) |
将指定的字符集文件解析成文档。 |
static Document parse(String html) |
将给定的 html 代码解析成文档。 |
static String clean(String bodyHtml, Whitelist whitelist) |
从输入 HTML 返回安全的 HTML,通过解析输入 HTML 并通过允许的标签和属性的白名单进行过滤。 |
Jsoup 类的其他重要方法可以参见 - https://jsoup.org/apidocs/org/jsoup/Jsoup.html
Document 类
该类表示通过 Jsoup 库加载 HTML 文档。可以使用此类执行适用于整个 HTML 文档的操作。
Element 类的重要方法可以参见 - http://jsoup.org/apidocs/org/jsoup/nodes/Document.html 。
Element 类
HTML 元素是由标签名称,属性和子节点组成。 使用 Element 类,您可以提取数据,遍历节点和操作 HTML。
Element 类的重要方法可参见 - http://jsoup.org/apidocs/org/jsoup/nodes/Element.html 。
JSoup 应用实例
加载文档
从 URL 加载文档:使用
Jsoup.connect()方法Document doc1 = Jsoup.connect("https://www.baidu.com/").get();从文件加载文档:使用
Jsoup.parse()方法Document doc2 = Jsoup.parse(new File("D:/test/jsontest.html"), "utf-8");从 String 加载文档:使用
Jsoup.parse()方法String html = "<html><head><title>First parse</title></head>" + "<body><p>Parsed HTML into a doc.</p></body></html>"; Document doc3 = Jsoup.parse(html);
获取元素
以 百度首页为例:
Document document = Jsoup.connect("https://www.baidu.com/").get();获取标题
System.out.println(document.title());获取页面的 Fav 图标
假设
favicon图像将是 HTML 文档的<head>部分中的第一个图像,可以使用下面的代码:String favImage = ""; Element element = document.head().select("link[href~=.*\\.(ico|png)]").first(); if (element == null) { element = document.head().select("meta[itemprop=image]").first(); if (element != null) { favImage = element.attr("content"); } } else { favImage = element.attr("href"); } System.out.println(favImage); // /favicon.ico获取页面中的所有链接
Element 类提供了 attr () 和 text () 方法来返回链接的链接和对应的文本。
Elements links = document.select("a[href]"); for (Element link : links) { System.out.println(link.text() + " - " + link.attr("href")); }结果如下:
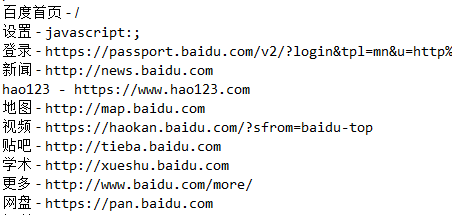
获取页面中的所有图像
调用
select()方法传递"img[src~=(?i)\\.(png|jpe?g|gif)]"正则表达式作为参数,以便它可以打印png,jpeg或gif类型的图像。Elements images = document.select("img[src~=(?i)\\.(png|jpe?g|gif)]"); for (Element image : images) { System.out.println(image.attr("alt") + " - " + image.attr("src")); }结果如下:
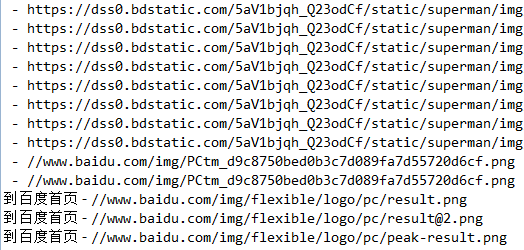
获取 URL 的元信息
String description = document.select("meta[name=description]").get(0).attr("content"); System.out.println(description); // 全球最大的中文搜索引擎、致力于让网民更便捷地获取信息,找到所求。百度超过千亿的中文网页数据库,可以瞬间找到相关的搜索结果。在 HTML 页面中获取表单属性
Element formElement = document.getElementById("form"); Elements inputElements = formElement.getElementsByTag("input"); for (Element inputElement : inputElements) { String key = inputElement.attr("name"); String value = inputElement.attr("value"); System.out.println("Param name: " + key + ", Param value: " + value); }结果如下:
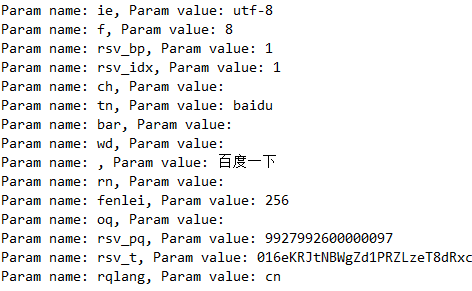
更新元素
只要您使用上述方法找到您想要的元素;可以使用 Jsoup API 来更新这些元素的属性或 innerHTML。
例如,想更新文档中存在的 “rel = nofollow” 的所有链接。
Document document = Jsoup.parse(new File("D:/test/jsontest.html"), "utf-8");
Elements links = document.select("a[href]");
links.attr("rel", "nofollow");消除不信任的 HTML
假设在应用程序中,想显示用户提交的 HTML 片段。 例如 用户可以在评论框中放入 HTML 内容。 这可能会导致非常严重的问题,如果您允许直接显示此 HTML。 用户可以在其中放入一些恶意脚本,并将用户重定向到另一个脏网站。
为了清理这个 HTML,Jsoup 提供 Jsoup.clean() 方法。 此方法期望 HTML 格式的字符串,并将返回清洁的 HTML。 要执行此任务,Jsoup 使用白名单过滤器。 jsoup 白名单过滤器通过解析输入 HTML (在安全的沙盒环境中) 工作,然后遍历解析树,只允许将已知安全的标签和属性 (和值) 通过清理后输出。
它不使用正则表达式,这对于此任务是不合适的。
清洁器不仅用于避免 XSS,还限制了用户可以提供的元素的范围:您可以使用文本,强元素,但不能构造 div 或表元素。
String dirtyHTML = "<p><a href='https://www.baidu.com/' onclick='sendCookiesToMe()'>Link</a></p>";
String cleanHTML = Jsoup.clean(dirtyHTML, Whitelist.basic());
System.out.println(cleanHTML);执行后输出结果如下:
<p><a href="https://www.baidu.com/" rel="nofollow">Link</a></p>