ElasticsearchRestTemplate 查询 API 示例
ElasticsearchRestTemplate
ElasticsearchRestTemplate 是 spring-data-elasticsearch 项目中的一个类,和其他 spring 项目中的 template 类似。
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>分页搜索
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
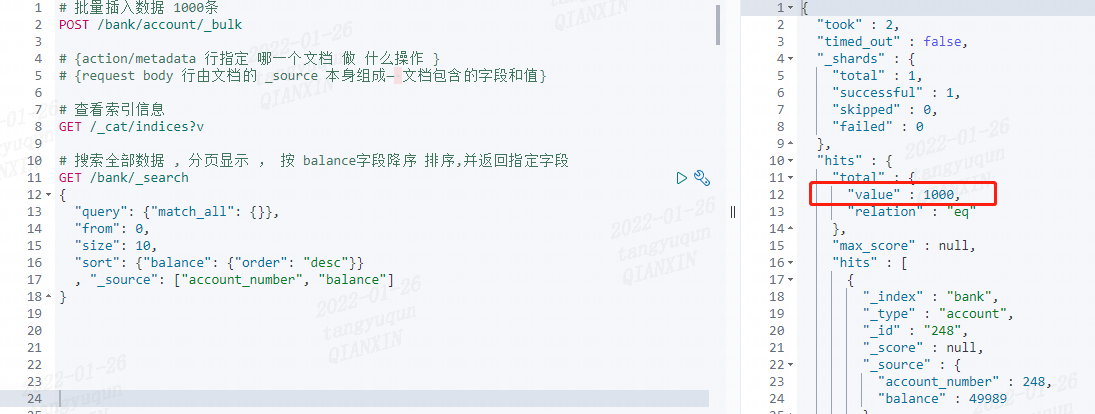
@Test
/** 搜索全部数据 , 分页显示 , 按 balance字段降序 排序 */
public void test1() {
// 构建查询条件(搜索全部)
MatchAllQueryBuilder queryBuilder1 = QueryBuilders.matchAllQuery();
// 分页
Pageable pageable = PageRequest.of(0, 5);
// 排序
FieldSortBuilder balance = new FieldSortBuilder("balance").order(SortOrder.DESC);
// 执行查询
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withQuery(queryBuilder1)
.withPageable(pageable)
.withSort(balance)
.build();
SearchHits<EsAccount> searchHits = elasticsearchRestTemplate.search(query, EsAccount.class);
//封装page对象
List<EsAccount> accounts = new ArrayList<>();
for (SearchHit<EsAccount> hit : searchHits) {
accounts.add(hit.getContent());
}
Page<EsAccount> page = new PageImpl<>(accounts,pageable,searchHits.getTotalHits());
//输出分页对象
System.out.println(page.getTotalPages());
System.out.println(page.getTotalElements());
}条件搜索
@Test
/** 条件搜索 */
public void test2() {
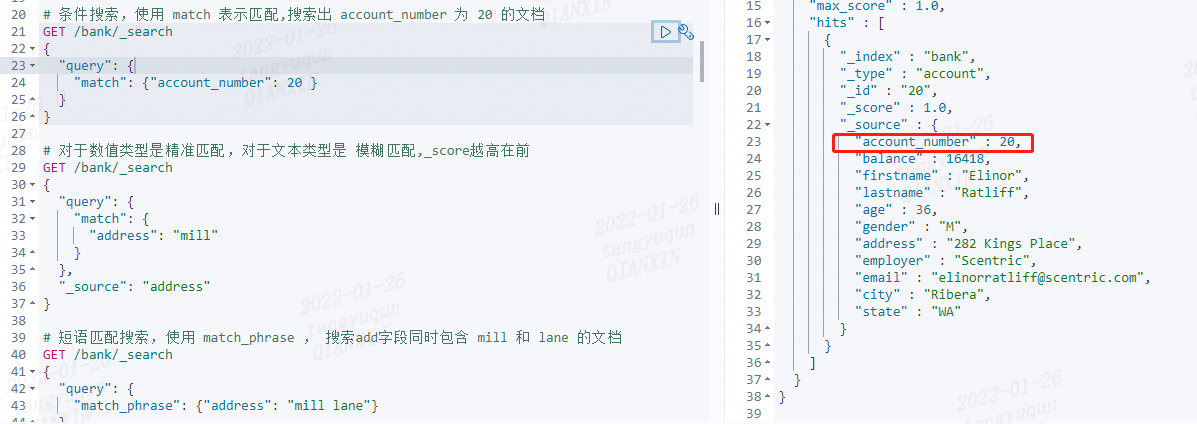
// 搜索出 account_number 为 20 的文档
TermQueryBuilder builder = QueryBuilders.termQuery("account_number", 20);
// 对于数值类型是精准匹配,对于文本类型是 模糊匹配,_score越高在前
TermQueryBuilder builder1 = QueryBuilders.termQuery("address", "mill");
// 搜索add字段同时包含 mill lane 的文档
TermQueryBuilder builder2 = QueryBuilders.termQuery("address", "mill lane");
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withQuery(builder1)
.build();
SearchHits<EsAccount> searchHits = elasticsearchRestTemplate.search(query, EsAccount.class);
for (SearchHit<EsAccount> hit : searchHits) {
System.out.println(hit.getContent());
}
}组合搜索
@Test
/** 组合搜索 bool*/
public void test3() {
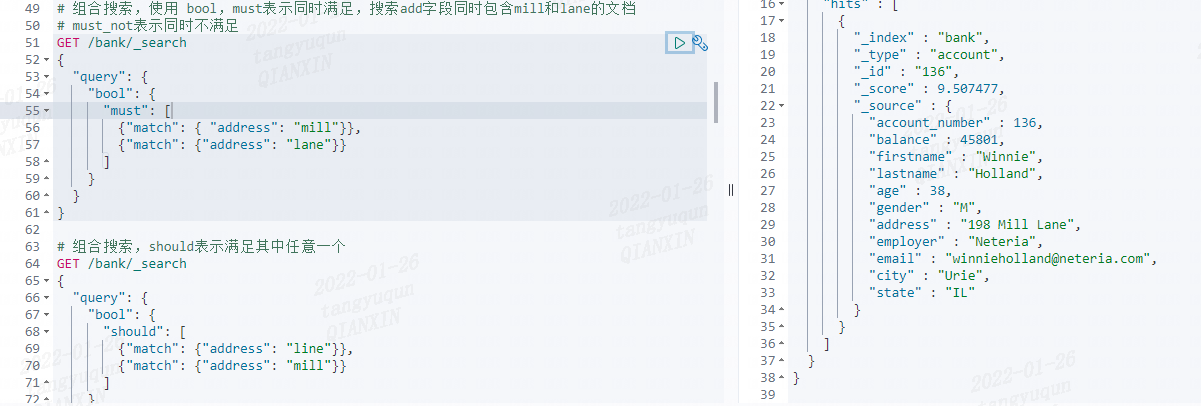
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// must表示同时满足,should满足其中一个,must_not表示同时不满足
boolQueryBuilder.must(QueryBuilders.matchQuery("address", "mill"));
boolQueryBuilder.must(QueryBuilders.matchQuery("address", "lane"));
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.build();
SearchHits<EsAccount> searchHits = elasticsearchRestTemplate.search(query, EsAccount.class);
for (SearchHit<EsAccount> hit : searchHits) {
System.out.println(hit.getContent());
}
}过滤搜索
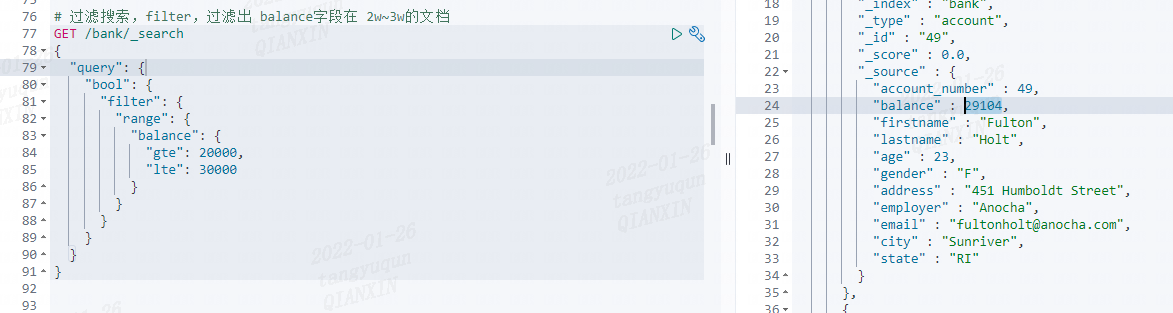
filter,过滤出 balance 字段在 2w~3w 的文档
@Test
/** 过滤搜索 */
public void test4() {
// 构建条件
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
RangeQueryBuilder balance = QueryBuilders.rangeQuery("balance").gte(20000).lte(30000);
boolQueryBuilder.filter(balance);
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.build();
SearchHits<EsAccount> searchHits = elasticsearchRestTemplate.search(query, EsAccount.class);
for (SearchHit<EsAccount> hit : searchHits) {
System.out.println(hit.getContent());
}
}聚合搜索
聚合搜索,aggs,类似于 group by,对 state 字段进行聚合,
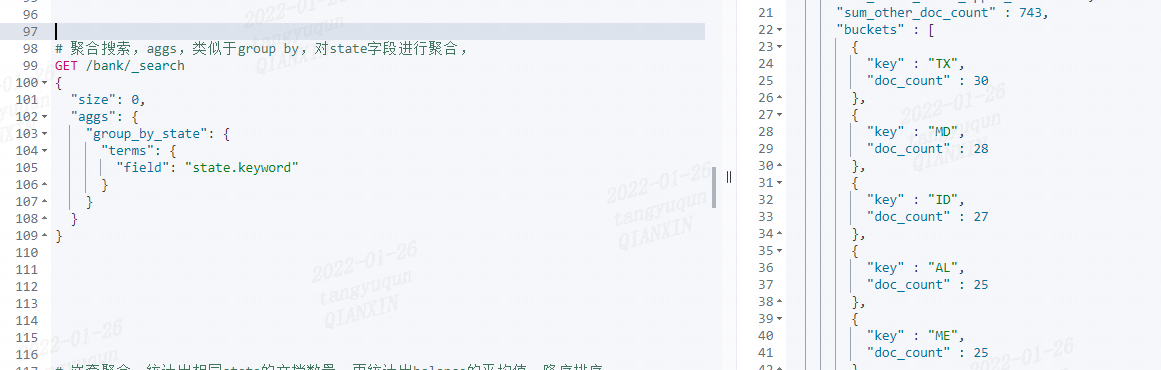
@Test
/** 聚合搜索 ,对state字段进行聚合*/
public void test5() {
NativeSearchQuery query = new NativeSearchQueryBuilder()
.addAggregation(AggregationBuilders.terms("count").field("state.keyword"))
.build();
SearchHits<EsAccount> searchHits = elasticsearchRestTemplate.search(query, EsAccount.class);
//取出聚合结果
Aggregations aggregations = searchHits.getAggregations();
Terms terms = (Terms) aggregations.asMap().get("count");
for (Terms.Bucket bucket : terms.getBuckets()) {
String keyAsString = bucket.getKeyAsString(); // 聚合字段列的值
long docCount = bucket.getDocCount(); // 聚合字段对应的数量
System.out.println(keyAsString + " " + docCount);
}
}嵌套聚合
统计出相同 state 的文档数量,再统计出 balance 的平均值,降序排序
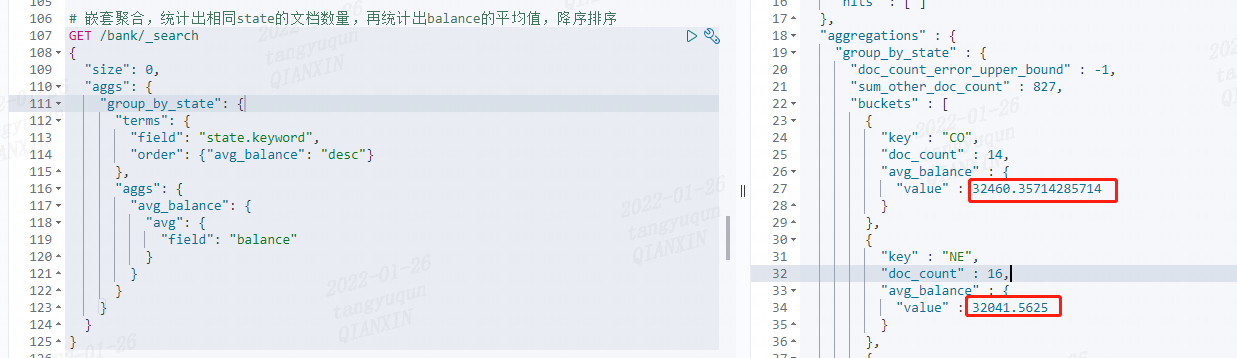
@Test
/** 嵌套聚合,统计出相同state的文档数量,再统计出balance的平均值,降序排序 */
public void test6() {
// 创建聚合查询条件
TermsAggregationBuilder stateAgg = AggregationBuilders.terms("count").field("state.keyword");
AvgAggregationBuilder balanceAgg = AggregationBuilders.avg("avg_balance").field("balance");
// 嵌套
stateAgg.subAggregation(balanceAgg);
// 按balance的平均值降序排序
stateAgg.order(BucketOrder.aggregation("avg_balance", false));
NativeSearchQuery build = new NativeSearchQueryBuilder()
.addAggregation(stateAgg)
.build();
//执行查询
SearchHits<EsAccount> searchHits = elasticsearchRestTemplate.search(build, EsAccount.class);
// 取出聚合结果
Aggregations aggregations = searchHits.getAggregations();
Terms terms = (Terms) aggregations.asMap().get("count");
for (Terms.Bucket bucket : terms.getBuckets()) {
// state : count : avg
ParsedAvg avg = bucket.getAggregations().get("avg_balance");
System.out.println(bucket.getKeyAsString() + " " + bucket.getDocCount() + " " + avg.getValueAsString());
}
}范围聚合
按字段的范围进行分段聚合,按 age 字段 [20,30],[30,40],[40,50], 之后按 gender 统计文档个数和 balance 的平均值
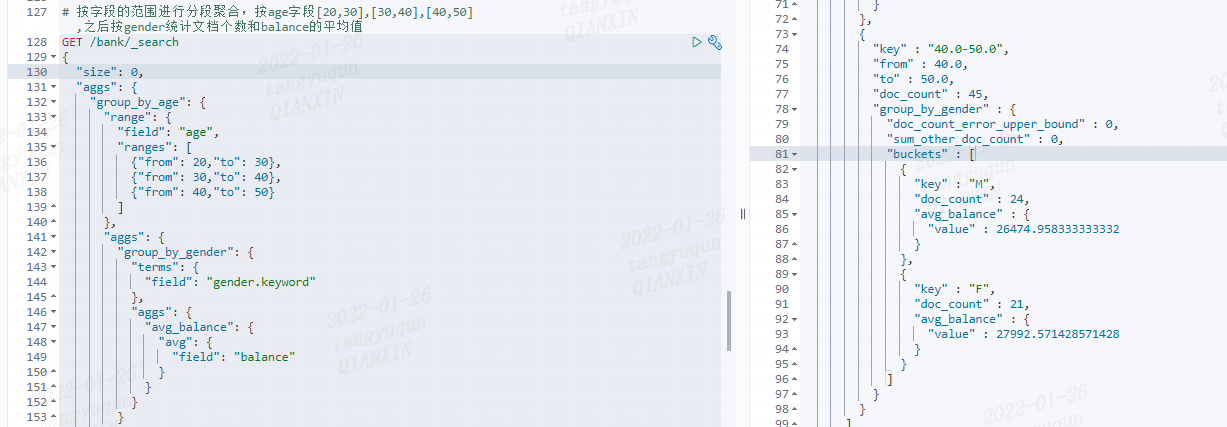
@Test
/** 按字段的范围进行分段聚合,按age字段[20,30],[30,40],[40,50],之后按gender统计文档个数和balance的平均值 */
public void test7(){
// 创建聚合查询条件
RangeAggregationBuilder group_by_age =
AggregationBuilders.range("group_by_age").field("age")
.addRange(20, 30).addRange(30, 40).addRange(40, 50);
TermsAggregationBuilder count = AggregationBuilders.terms("count").field("gender.keyword");
AvgAggregationBuilder balanceAgg = AggregationBuilders.avg("avg_balance").field("balance");
//嵌套
group_by_age.subAggregation(count);
count.subAggregation(balanceAgg);
NativeSearchQuery query = new NativeSearchQueryBuilder()
.addAggregation(group_by_age)
.build();
SearchHits<EsAccount> searchHits = elasticsearchRestTemplate.search(query, EsAccount.class);
ParsedRange parsedRange = searchHits.getAggregations().get("group_by_age");
for (Range.Bucket bucket : parsedRange.getBuckets()) {
// "key" : "20.0-30.0", "doc_count" : 451,
System.out.println(bucket.getKeyAsString()+" : "+bucket.getDocCount());
Terms group_by_gender = bucket.getAggregations().get("count");
for (Terms.Bucket genderBucket : group_by_gender.getBuckets()) {
// "key" : "M", "doc_count" : 232, "key" : "F", "doc_count" : 219,
System.out.println(genderBucket.getKeyAsString() +" : "+ genderBucket.getDocCount());
ParsedAvg balanceAvg = genderBucket.getAggregations().get("avg_balance");
System.out.println(balanceAvg.getValueAsString());
}
System.out.println("-----------\n");
}
}相关文章