0%
MySQL 锁表问题的排查和处理
我们可以用下面三张 INFORMATION_SCHEMA 库中的表来查原因:
- innodb_trx:当前运行的所有事务
- innodb_locks:当前出现的锁
- innodb_lock_waits:锁等待的对应关系
fastjson 常用汇总
fastjson
- GitHub:https://github.com/alibaba/fastjson
- 文档:https://github.com/alibaba/fastjson/wiki/Quick-Start-CN
依赖引入
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>
ElementUI 实现文件上传下载
通过 ElementUI 实现文件上传下载。
Vue 之 ElementUI 动态创建输入框
动态添加属性
示例代码
<template>
<div>
<el-form :model="dataForm" label-width="100px">
<el-form-item
v-for="(domain, index) in dataForm.domains"
:label=domain.key
:key="domain.key"
:prop="'domains.' + index + '.value'"
:rules="{ required: true, message: '属性不能为空', trigger: 'blur'}">
<el-row>
<el-col :span="6">
<el-input v-model="domain.value"></el-input>
</el-col>
<el-col :span="4">
<el-button @click.prevent="removeDomain(domain)">删除</el-button>
</el-col>
</el-row>
</el-form-item>
<el-form-item>
<el-button type="primary" @click="submitForm('dataForm')">提交属性 </el-button>
<el-button @click="addDomain">新增属性</el-button>
</el-form-item>
</el-form>
</div>
</template>
<script>
export default {
data() {
return {
dataForm: {
domains: [{
key: '属性a',
value: 'aaa'
}, {
key: '属性b',
value: 'bbb'
}]
}
}
},
methods: {
removeDomain(item) {
var index = this.dataForm.domains.indexOf(item)
if (index !== -1) {
this.dataForm.domains.splice(index, 1)
}
},
addDomain() {
this.$prompt('请输入属性', '提示', {
confirmButtonText: '确定',
cancelButtonText: '取消'
}).then(({ value }) => {
this.dataForm.domains.push({
value: '',
key: value
})
}).catch(() => {
this.$message({
type: 'info',
message: '取消输入'
})
})
}
}
}
</script>实现效果
默认:
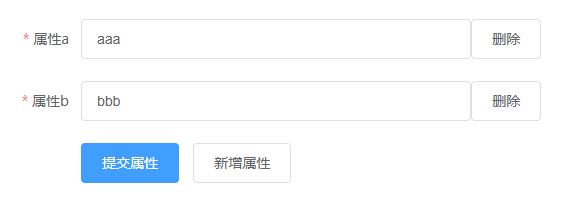
增加属性:
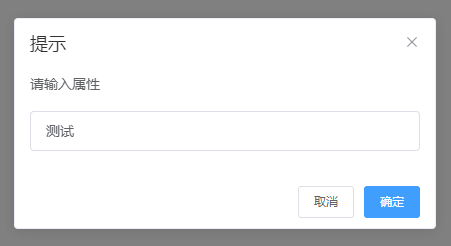
增加后:
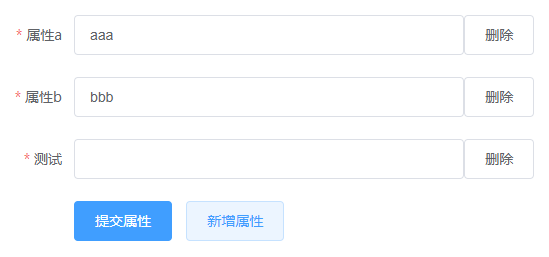
删除:
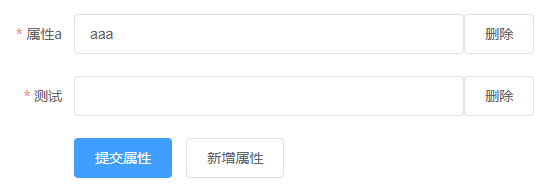
动态添加输入框
示例代码
<template>
<div>
<el-form :model="dataForm" label-width="100px" size="small">
<el-form-item label="名称匹配" prop="name">
<el-row >
<span v-for="(domain, index) in dataForm.domains">
<el-col :span="5">
<el-input v-model="domain.value"></el-input>
</el-col>
<el-col :span="2">
<el-button @click="removeDomain(index)">删除</el-button>
</el-col>
</span>
<el-col :span="2">
<el-button @click="addDomain">新增</el-button>
</el-col>
</el-row>
</el-form-item>
<el-form-item>
<el-button type="primary" @click="submitForm('dataForm')">提交属性 </el-button>
</el-form-item>
</el-form>
</div>
</template>
<script>
export default {
data() {
return {
dataForm: {
domains: [{value:"aaa"},{value:"bbb"},{value:"ccc"}]
}
}
},
methods: {
removeDomain(index) {
this.dataForm.domains.splice(index, 1)
},
addDomain() {
this.dataForm.domains.push({value:""})
}
}
}
</script>实现效果

优化效果
通过 clearable @clear='' 来实现删除效果。
<template>
<div>
<el-form :model="dataForm" label-width="100px" size="small">
<el-form-item label="名称匹配" prop="name">
<el-row >
<el-col :span="3" v-for="(domain, index) in dataForm.domains" >
<el-input v-model="domain.value" clearable @clear="removeDomain(index)"></el-input>
</el-col>
<el-col :span="2">
<el-button @click="addDomain">新增</el-button>
</el-col>
</el-row>
</el-form-item>
<el-form-item>
<el-button type="primary" @click="submitForm('dataForm')">提交属性 </el-button>
</el-form-item>
</el-form>
</div>
</template>
Bootstrap Table 列宽拖动的方法
Bootstrap
- 官方插件:https://bootstrap-table.com/docs/extensions/resizable/
方法一:colResizable
- 官网介绍:http://www.bacubacu.com/colresizable/
- GitHub:https://github.com/alvaro-prieto/colResizable
引入依赖
<script type="text/javascript" src="http://www.bacubacu.com/colresizable/js/colResizable-1.6.min.js"></script>示例代码
<html>
<title>colResizable</title>
<link rel="stylesheet" href="http://netdna.bootstrapcdn.com/bootstrap/3.1.1/css/bootstrap.min.css">
<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.12.4/jquery.min.js"></script>
<script type="text/javascript" src="http://www.bacubacu.com/colresizable/js/colResizable-1.6.min.js"></script>
<script type="text/javascript">
$(function(){
$("#table").colResizable();
})
</script>
</head>
<body>
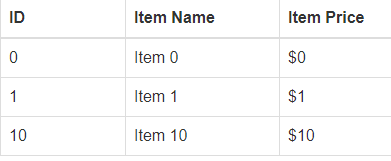
<table id="table" class="table table-bordered table-hover">
<thead>
<tr>
<th style="width: 19.09%;" >ID</th>
<th style="width: 33.56%;" >Item Name</th>
<th style="width: 47.28%;" >Item Price</th>
</tr>
</thead>
<tbody>
<tr data-index="0">
<td>0</td>
<td>Item 0</td>
<td>$0</td>
</tr>
<tr data-index="1">
<td>1</td>
<td>Item 1</td>
<td>$1</td>
</tr>
<tr data-index="2">
<td>10</td>
<td>Item 10</td>
<td>$10</td>
</tr>
</tbody>
</table>
</body>方法二:resizableColumns
- GitHub:https://github.com/dobtco/jquery-resizable-columns
- 官方示例:http://dobtco.github.io/jquery-resizable-columns/
引入依赖
<script src="js/main/jquery.resizableColumns.min.js"></script>
<link rel="stylesheet" href="css/main/jquery.resizableColumns.css">示例代码
<html>
<head>
<link rel="stylesheet" href="http://netdna.bootstrapcdn.com/bootstrap/3.1.1/css/bootstrap.min.css">
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.10.2/jquery.min.js"></script>
<link rel="stylesheet" href="http://dobtco.github.io/jquery-resizable-columns/dist/jquery.resizableColumns.css">
<script src="http://dobtco.github.io/jquery-resizable-columns/dist/jquery.resizableColumns.min.js"></script>
<body>
<table id="table" class="table table-bordered table-hover">
<thead>
<tr>
<th style="width: 19.09%;" >ID</th>
<th style="width: 33.56%;" >Item Name</th>
<th style="width: 47.28%;" >Item Price</th>
</tr>
</thead>
<tbody>
<tr data-index="0">
<td>0</td>
<td>Item 0</td>
<td>$0</td>
</tr>
<tr data-index="1">
<td>1</td>
<td>Item 1</td>
<td>$1</td>
</tr>
<tr data-index="2">
<td>10</td>
<td>Item 10</td>
<td>$10</td>
</tr>
</tbody>
</table>
</body>
<script>
$(function(){
$("#table").resizableColumns({
store: window.store
});
});
</script>